背景
开发的日志数量及单位日志的大小一直在增加,但ES集群整体架构不变,不扩容、不升级,导致ES集群无法满足当前实时索引及查询的需求,频繁出现日志索引延迟报警。
升级计划
本次优化操作不扩容ES数据节点,而是替换现有配置较差的ES数据节点,具体原因如下:
- ES索引效率不和ES数据节点数量成正比,节点数量越多,但节点硬件配置低,反而会影响索引效率,遵循“木桶效应”
- 服务器及机房机架位有限,无法无限制的增加机器
升级步骤
具体升级操作步骤如下:
- 两台高配ES节点上架,部署ES服务,同时启动ES服务,数据开始平衡,平均分布到每个ES数据节点
- 待数据平衡完毕后,关闭其中一台低配ES节点的ES服务,数据开始平衡,平均分布到每个ES数据节点
- 待数据平衡完毕后,关闭另外一台低配ES节点的ES服务,数据开始平衡,平均分布到每个ES数据节点,待平衡完毕后,升级操作完毕
后续操作
升级完毕后,发现ES索引方面已无瓶颈,但索引速度还是提不上来,而且只有某个topic的速度上不来。
这边考虑到该topic所在的logstash indexer服务器跑了较多logstash indexer服务,可能是indexer到了瓶颈,于是将该topic的logstash indexer服务迁移到了另外一台负载较低的机器上。
服务启动后,发现网卡速度直线飙升,索引速度迅速提高,并且ES数据节点负载也在可接受范围内,索引效率基本恢复到稳定状态。
压测数据
在优化之前,索引的位置与当前位置大概相差2小时左右的offset,所以在优化后,索引速率是按照消费端最大速率来跑的,得到的数据可以视为瓶颈数据:
单个topic索引率达到10k/s:
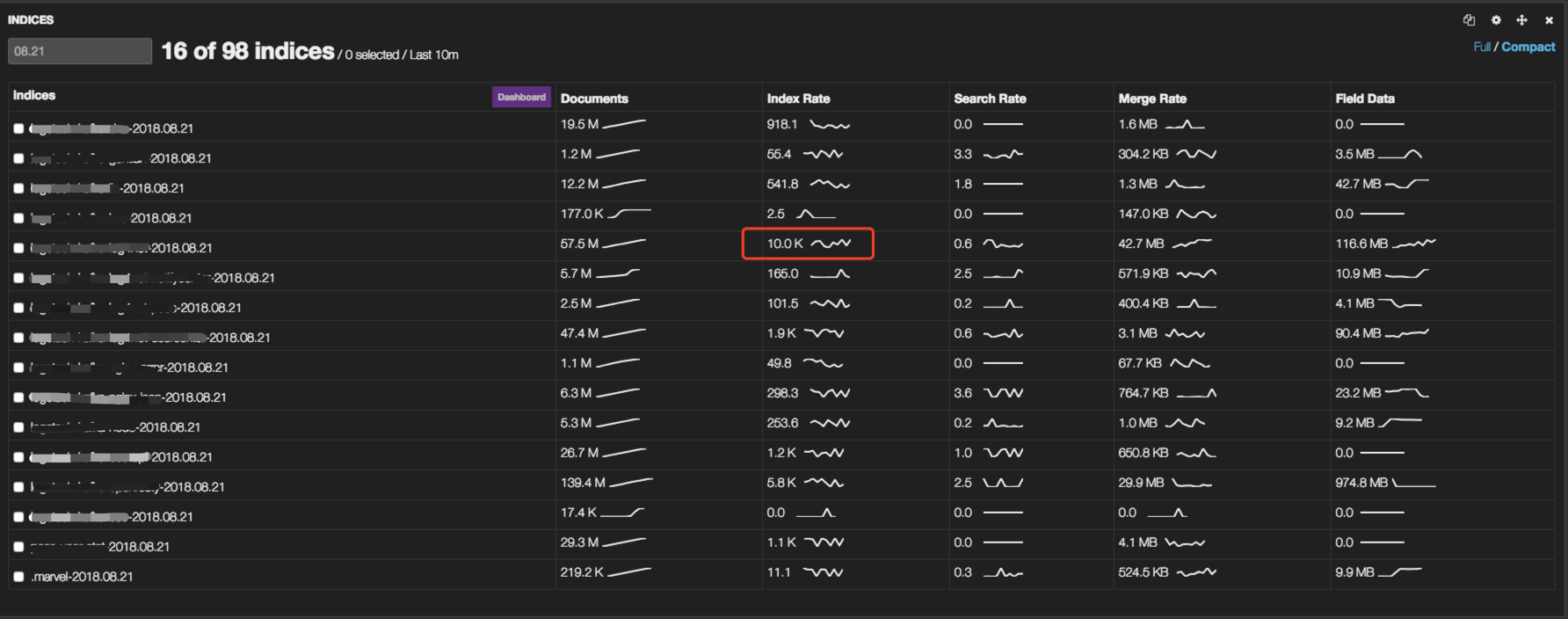
集群索引率达到25k/s:
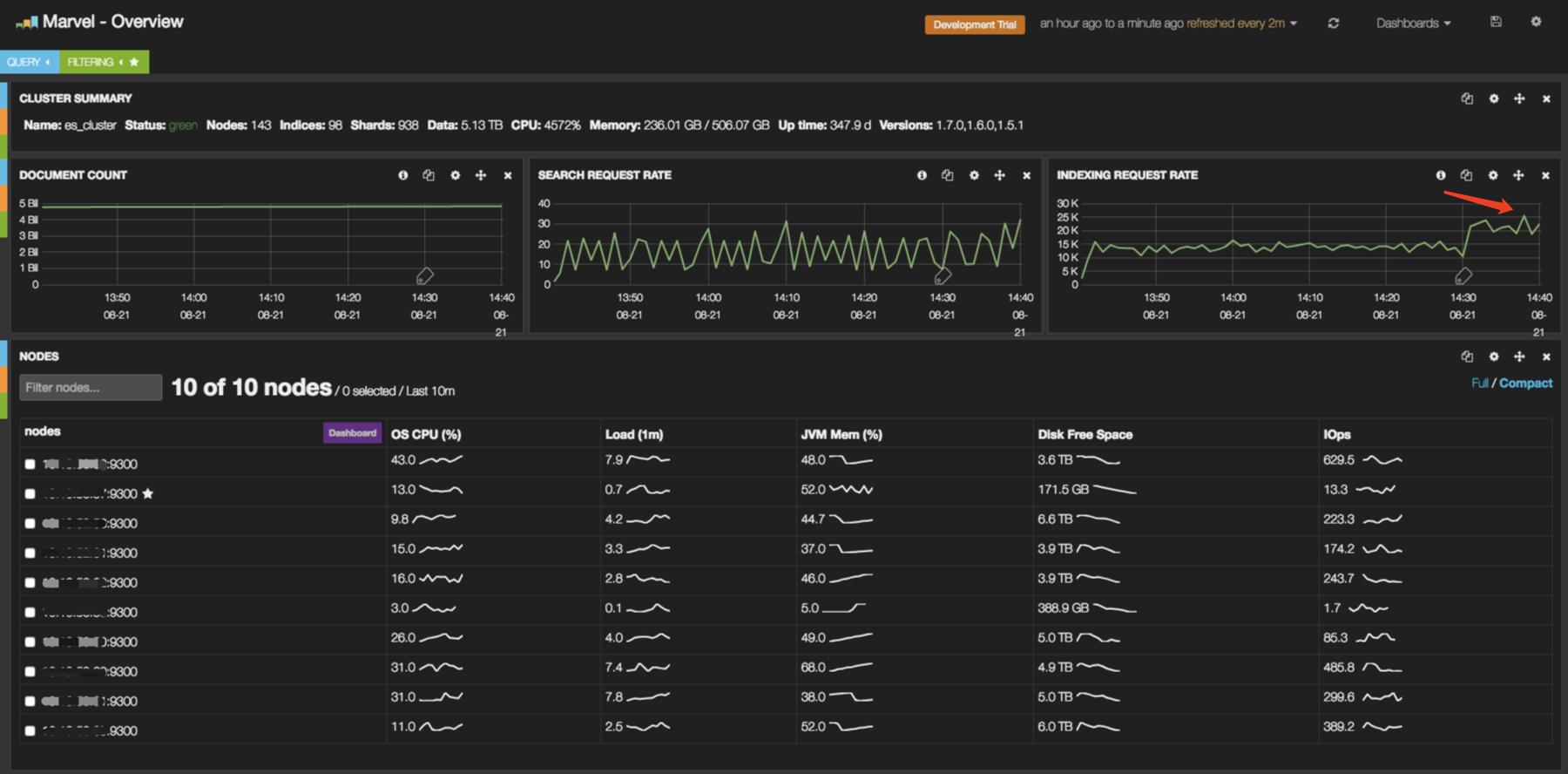
原则上,如果要测试集群总索引率,需要增加消费端数量,一直增加到ES集群出现大量GC,索引率无法再上升为止。
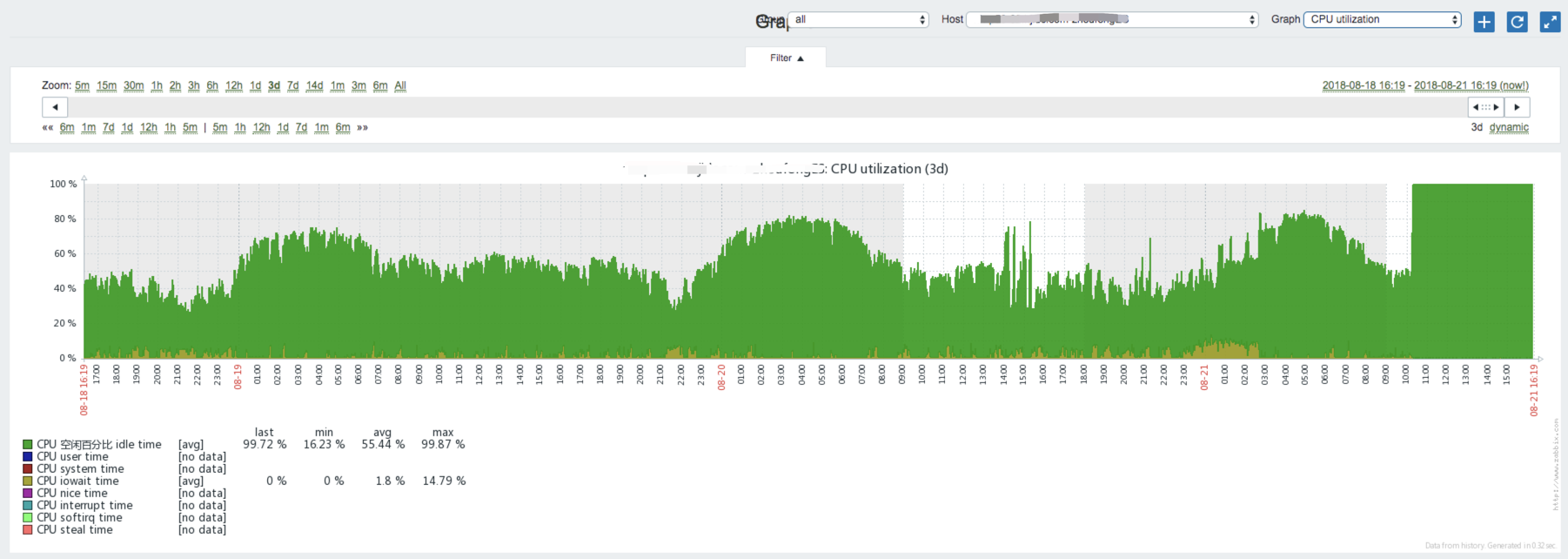
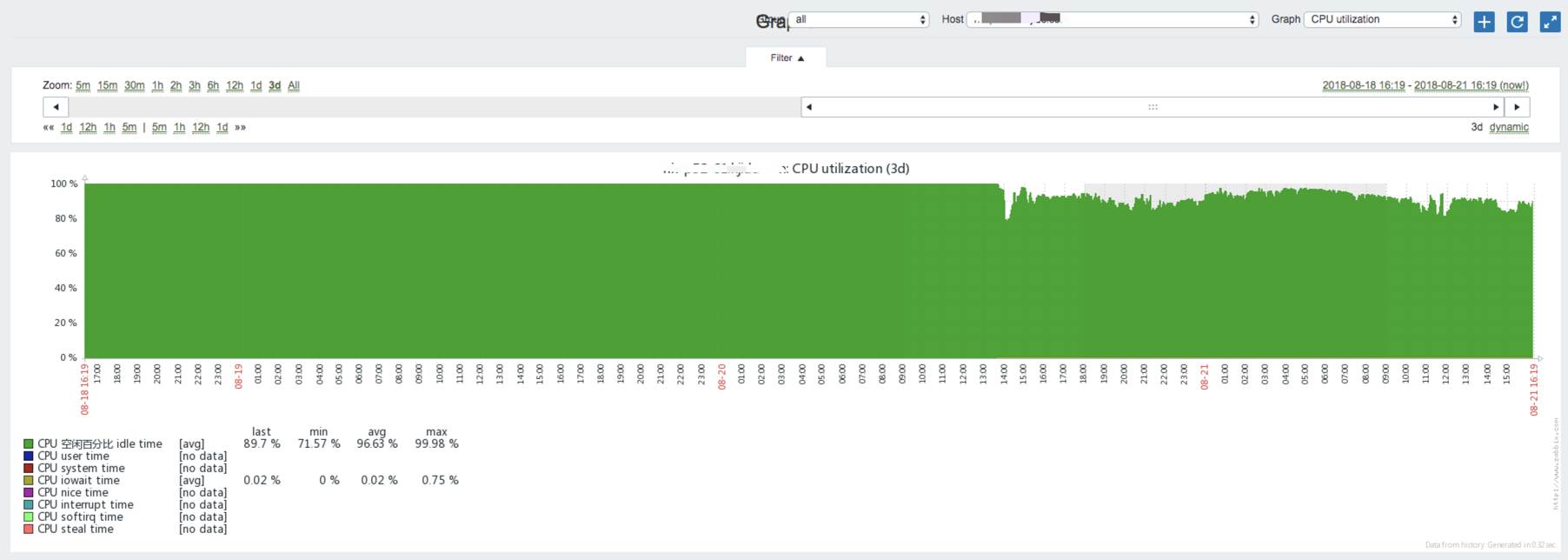
CPU利用率对比
老的低配CPU利用率(8核2.4kMhz),平均利用率超50%,且有cpu io wait:
新的高配CPU利用率(24核2.1kMhz),平均利用率不超15%,无cpu io wait:
后记
确保每台ES数据节点服务器硬件“达标”,同时合理分配Logstash indexer,是保证ES集群索引高效的重要条件!