背景
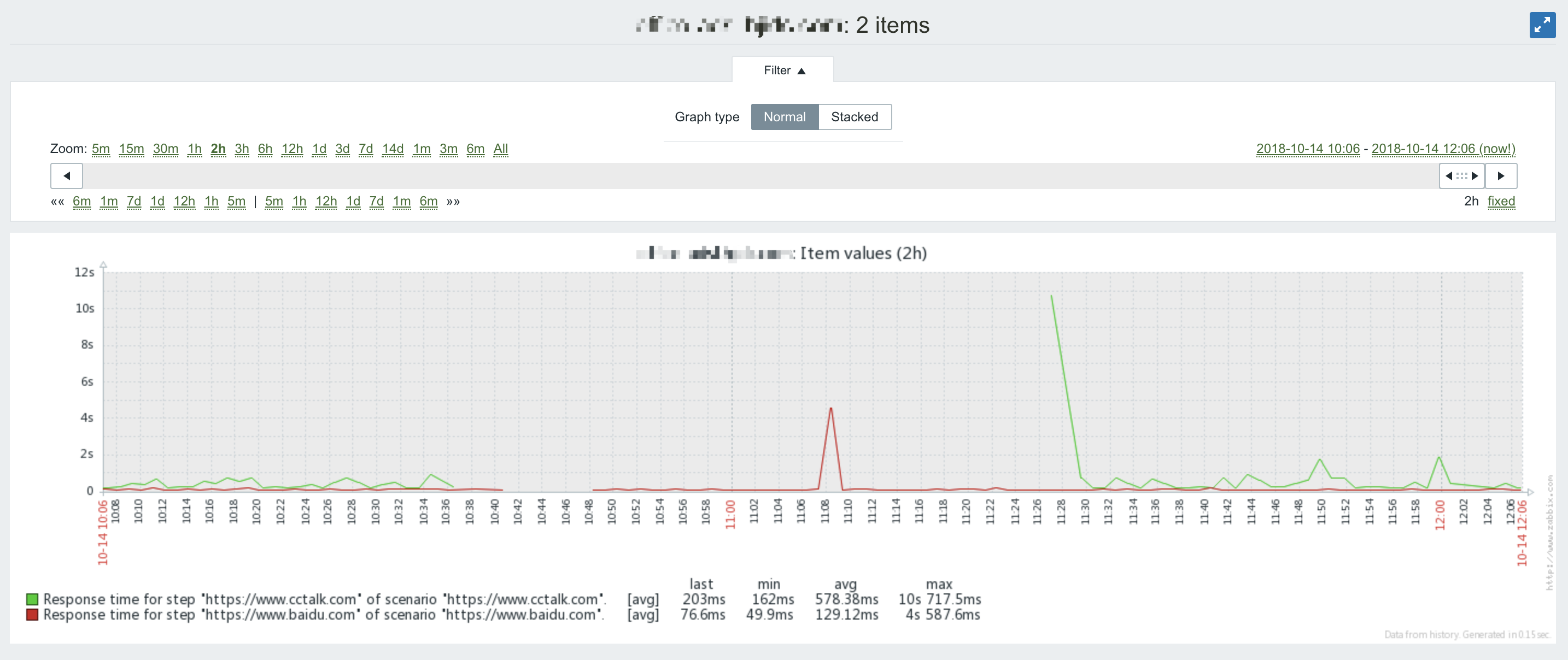
周日上午,公司微信群突然炸,在公司上班的同学反馈公司的网站都打不开了,立刻开始扑火。
问题
从群里的反馈来看,外网不受影响,只有公司办公网用户反馈故障,说明时办公网内部问题。同时只反馈打开公司网站有问题,百度、微博等外部站点均正常。
由于我司办公网DNS对于自己的权威域及三方域名解析是单独分开的,自己的权威域由BIND递归DNS完成,而三方域名解析是由DNSMASQ转发DNS完成,于是排查的重点放在BIND上。
连上公司VPN,登录内网后手工解析排查了下,确实如反馈的一样:
- 内网解析失败,
status字段为:SERVFAIL;
$ dig wiki.yeshj.com
; <<>> DiG 9.10.6 <<>> wiki.yeshj.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: SERVFAIL, id: 20414
;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 4096
;; QUESTION SECTION:
;wiki.yeshj.com. IN A
;; Query time: 48 msec
;; SERVER: <dns_ip>#53(<dns_ip>)
;; WHEN: Sun Oct 14 11:12:22 CST 2018
;; MSG SIZE rcvd: 43
- 第三方域名解析正常,
status字段为:NOERROR:
$ dig www.weibo.com @<dns_ip>
; <<>> DiG 9.10.6 <<>> www.weibo.com @<dns_ip>
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 13538
;; flags: qr rd ra; QUERY: 1, ANSWER: 3, AUTHORITY: 0, ADDITIONAL: 0
;; QUESTION SECTION:
;www.weibo.com. IN A
;; ANSWER SECTION:
www.weibo.com. 300 IN A 180.149.134.141
www.weibo.com. 300 IN A 180.149.134.142
www.weibo.com. 300 IN A 180.149.138.56
;; Query time: 53 msec
;; SERVER: <dns_ip>#53(<dns_ip>)
;; WHEN: Sun Oct 14 11:15:12 CST 2018
;; MSG SIZE rcvd: 79
登录递归DNS,直觉以为是不是磁盘空间用完了,或者内存溢出,结果磁盘空间正常,但16G内存都被吃光了:
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/vda3 151G 27G 117G 19% /
tmpfs 7.8G 12K 7.8G 1% /dev/shm
/dev/vda1 976M 67M 859M 8% /boot
# free -m
total used free shared buffers cached
Mem: 15950 15121 828 0 148 14168
-/+ buffers/cache: 805 15145
Swap: 6143 0 6143
再查看系统日志,马上就发现了问题:
# tail -f /var/log/messages
Oct 14 11:35:40 pr-v17-125 named[4178]: unable to rename log file '/var/log/query.log' to '/var/log/query.log.0': permission denied
Oct 14 11:35:40 pr-v17-125 named[4178]: unable to rename log file '/var/log/query.log' to '/var/log/query.log.0': permission denied
Oct 14 11:35:40 pr-v17-125 named[4178]: unable to rename log file '/var/log/query.log' to '/var/log/query.log.0': permission denied
...
系统日志抛DNS创建新查询日志失败错误,原因是named服务由named用户启动,而named用户不具备创建/var/log/query.log.0文件的权限,所以造成解析服务异常。
那源查询日志文件到底有多大呢?印象当中从部署完过后,从来都没有删过这个日志,怎么会突然故障了呢?
# ll -h /var/log/query.log
-rw-r--r-- 1 named named 22G Oct 14 11:35 /var/log/query.log
22G,确实很大了,但为啥是22G出问题,不是2G,也不是220G时出问题呢?怀疑和日志具体大小无关,而是这个时候正好内存全部耗尽了,才导致了故障。
缓解
解决线上问题优先,这边先重启了下named服务(释放内存),发现可以解析了:
# /etc/init.d/named restart
Stopping named: . [ OK ]
Starting named: [ OK ]
但有可能再崩,所以又立即清空了/var/log/query.log日志文件:
# > /var/log/query.log
到这边,问题已经得到缓解,但这个操作只能解燃眉之急,以后还是会有类似问题发生,想要一劳永逸,必须解决权限问题!
其实也容易,调整下BIND服务配置文件就可以了:
# cp /etc/named.conf /etc/named.conf.bak
# vi /etc/named.conf
原BIND配置文件:
channel query_log {
file "/var/log/query.log" versions 15 size 20m;
severity dynamic;
print-time yes;
print-category yes;
print-severity yes;
};
调整后的BIND配置文件:
channel query_log {
file "/var/log/named/query.log" versions 3 size 30M;
severity dynamic;
print-time yes;
print-category yes;
print-severity yes;
};
同时创建named日志子文件夹,并赋named权限:
# mkdir /var/log/named
# chown named:named /var/log/named
# /etc/init.d/named restart
Stopping named: . [ OK ]
Starting named: [ OK ]
这边因为用filebeat采集dns日志,所以还要更新filebeat配置文件,这边就不贴配置了。
后记
在部署任何一个应用服务时,不要给自己挖坑,譬如本次BIND服务,开启了日志,日志轮转并未生效,最后达到一定量级后直接崩,造成线上故障。
说白了还是懒,服务上线后,疏于对服务都管理,才导致这次故障发生。
打了日志,就要想到日志清理的问题,形成操作闭环,很基础的运维意识。
另外这个问题是由用户反馈的,但其实监控是有的,但就是没报警出来,这边更新了下报警策略,将报警通过微信发出,以缩短故障时间: