背景
某机房ELK集群索引出现延迟,但并非所有索引均出现延迟,上班后接到微信报警,开始排查问题。
该机房Kafka集群的Kafka服务及zookeeper服务分离,其中:
Kafka有3个数据节点,以下分别成为:Broker 0、Broker 1及Broker 2,版本为:kafka_2.10-0.10.2.0;zookeeper有5个节点作为zk集群;
问题
logstash indexer
由于是某个索引在早7点突然停止索引,推测可能是logstash indexer生成日志异常,故重启对应索引点logstash indexer,但重启后并未恢复,依然无索引,排除logstash的问题。
Kafka
查看Kafka服务器上分片数据,Broker 0上但物理log文件最后修改时间停留在早7点,说明很有可能是Kafka点问题了。
查看Kafka集群监控数据,发现Broker 0自早7点后,网卡入和出的带宽均几乎跌至0,Broker 1及Broker 2的入/出带宽虽有下降,但并未跌至0,这就解释了为什么部分索引仍然正常的现象。
分别查看Kafka应用日志:
Broker 0
[2018-10-30 07:00:26,553] INFO Deleting index /home/data/kafka-logs/__consumer_offsets-49/00000000261465893993.index.deleted (kafka.log.OffsetIndex)
[2018-10-30 07:00:26,553] INFO Deleting index /home/data/kafka-logs/__consumer_offsets-49/00000000261465893993.timeindex.deleted (kafka.log.TimeIndex)
[2018-10-30 07:00:34,049] INFO [GroupCoordinator 0]: Group kafka-influxdb with generation 148 is now empty (kafka.coordinator.GroupCoordinator)
[2018-10-30 07:00:34,072] INFO [GroupCoordinator 0]: Group logstash with generation 5700 is now empty (kafka.coordinator.GroupCoordinator)
[2018-10-30 07:00:39,237] WARN [GroupCoordinator 0]: Failed to write empty metadata for group kafka-influxdb: The group is rebalancing, so a rejoin is needed. (kafka.coordinator.GroupCoordinator)
Broker 1
[2018-10-30 07:00:34,755] WARN [ReplicaFetcherThread-0-0], Error in fetch kafka.server.ReplicaFetcherThread$FetchRequest@6a3b53b1 (kafka.server.ReplicaFetcherThread)
java.io.IOException: Connection to 0 was disconnected before the response was read
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1$$anonfun$apply$1.apply(NetworkClientBlockingOps.scala:114)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1$$anonfun$apply$1.apply(NetworkClientBlockingOps.scala:112)
at scala.Option.foreach(Option.scala:236)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1.apply(NetworkClientBlockingOps.scala:112)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1.apply(NetworkClientBlockingOps.scala:108)
at kafka.utils.NetworkClientBlockingOps$.recursivePoll$1(NetworkClientBlockingOps.scala:136)
at kafka.utils.NetworkClientBlockingOps$.kafka$utils$NetworkClientBlockingOps$$pollContinuously$extension(NetworkClientBlockingOps.scala:142)
at kafka.utils.NetworkClientBlockingOps$.blockingSendAndReceive$extension(NetworkClientBlockingOps.scala:108)
at kafka.server.ReplicaFetcherThread.sendRequest(ReplicaFetcherThread.scala:249)
at kafka.server.ReplicaFetcherThread.fetch(ReplicaFetcherThread.scala:234)
at kafka.server.ReplicaFetcherThread.fetch(ReplicaFetcherThread.scala:42)
at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:118)
at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:103)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:63)
[2018-10-30 07:04:29,410] INFO [Group Metadata Manager on Broker 1]: Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.GroupMetadataManager)
[2018-10-30 07:21:07,808] INFO Rolled new log segment for 'openresty-1' in 1 ms. (kafka.log.Log)
[2018-10-30 08:09:59,245] INFO Scheduling log segment 15751412496 for log openresty-1 for deletion. (kafka.log.Log)
[2018-10-30 08:10:59,245] INFO Deleting segment 15751412496 from log openresty-1. (kafka.log.Log)
[2018-10-30 08:10:59,246] INFO Deleting index /home/data/kafka-logs/openresty-1/00000000015751412496.index.deleted (kafka.log.OffsetIndex)
[2018-10-30 08:10:59,246] INFO Deleting index /home/data/kafka-logs/openresty-1/00000000015751412496.timeindex.deleted (kafka.log.TimeIndex)
Broker 2
[2018-10-30 07:00:34,894] WARN [ReplicaFetcherThread-0-0], Error in fetch kafka.server.ReplicaFetcherThread$FetchRequest@62ad57ab (kafka.server.ReplicaFetcherThread)
java.io.IOException: Connection to 0 was disconnected before the response was read
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1$$anonfun$apply$1.apply(NetworkClientBlockingOps.scala:114)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1$$anonfun$apply$1.apply(NetworkClientBlockingOps.scala:112)
at scala.Option.foreach(Option.scala:236)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1.apply(NetworkClientBlockingOps.scala:112)
at kafka.utils.NetworkClientBlockingOps$$anonfun$blockingSendAndReceive$extension$1.apply(NetworkClientBlockingOps.scala:108)
at kafka.utils.NetworkClientBlockingOps$.recursivePoll$1(NetworkClientBlockingOps.scala:136)
at kafka.utils.NetworkClientBlockingOps$.kafka$utils$NetworkClientBlockingOps$$pollContinuously$extension(NetworkClientBlockingOps.scala:142)
at kafka.utils.NetworkClientBlockingOps$.blockingSendAndReceive$extension(NetworkClientBlockingOps.scala:108)
at kafka.server.ReplicaFetcherThread.sendRequest(ReplicaFetcherThread.scala:249)
at kafka.server.ReplicaFetcherThread.fetch(ReplicaFetcherThread.scala:234)
at kafka.server.ReplicaFetcherThread.fetch(ReplicaFetcherThread.scala:42)
at kafka.server.AbstractFetcherThread.processFetchRequest(AbstractFetcherThread.scala:118)
at kafka.server.AbstractFetcherThread.doWork(AbstractFetcherThread.scala:103)
at kafka.utils.ShutdownableThread.run(ShutdownableThread.scala:63)
[2018-10-30 07:07:15,407] INFO [Group Metadata Manager on Broker 2]: Removed 0 expired offsets in 0 milliseconds. (kafka.coordinator.GroupMetadataManager)
[2018-10-30 07:37:45,240] INFO Scheduling log segment 15750827463 for log openresty-2 for deletion. (kafka.log.Log)
[2018-10-30 07:38:45,241] INFO Deleting segment 15750827463 from log openresty-2. (kafka.log.Log)
[2018-10-30 07:38:45,241] INFO Deleting index /home/data/kafka-logs/openresty-2/00000000015750827463.index.deleted (kafka.log.OffsetIndex)
[2018-10-30 07:38:45,276] INFO Deleting index /home/data/kafka-logs/openresty-2/00000000015750827463.timeindex.deleted (kafka.log.TimeIndex)
Broker 1及Broker 2都在报java.io.IOException: Connection to 0 was disconnected before the response was read这个错,而Broker 0啥异常都没有,推测出现了类似脑裂的问题,也即:Broker 1及Broker 2均无法与Broker 0通信了,集群间状态出现异常,导致的结果是Broker 0不再作为Kafka集群的一个节点,被集群剔除了。
通过报错日志搜了下Kafka源码,出现该异常报错的场景确实是在当Kafka数据节点(KafkaClient)失去连接(wasDisconnected())时才会抛的异常,并且正常来说应该是可以获取到建连失败节点的socket信息的,但在日志中,socket字段为0,说明获取KafkaClient的状态(response.destination())同样出现了问题:
/**
* Invokes `client.send` followed by 1 or more `client.poll` invocations until a response is received or a
* disconnection happens (which can happen for a number of reasons including a request timeout).
*
* In case of a disconnection, an `IOException` is thrown.
*
* This method is useful for implementing blocking behaviour on top of the non-blocking `NetworkClient`, use it with
* care.
*/
public static ClientResponse sendAndReceive(KafkaClient client, ClientRequest request, Time time) throws IOException {
client.send(request, time.milliseconds());
while (true) {
List<ClientResponse> responses = client.poll(Long.MAX_VALUE, time.milliseconds());
for (ClientResponse response : responses) {
if (response.requestHeader().correlationId() == request.correlationId()) {
if (response.wasDisconnected()) {
throw new IOException("Connection to " + response.destination() + " was disconnected before the response was read");
}
if (response.versionMismatch() != null) {
throw response.versionMismatch();
}
return response;
}
}
}
}
}
缓解
首先重启Broker 0Kafka服务,重启后大部分索引恢复,但仍有部分索引未恢复,随后再分别重启Broker 1及Broker 2,所有索引均恢复正常索引。
后记
由于急于恢复服务,出现故障时并未对现场做全面的数据分析,事后再查监控数据,发现有如下几个服务器性能指标异常:
- 服务器TCP连接数中,
Broker 0的close wait数量自早7点后直线飙升,推测是Broker 0故障后,原先与Broker 0建连的生产者(logstash shipper)并未超时断开,保留了大量tcp连接等待关闭,但这些连接为什么始终保持,而不是超时断开,zk重新分配给Broker 1及Broker 2,这里是个疑问。 - 重启
Broker 0后,Broker 0的close wait消失,established数量出现上升:
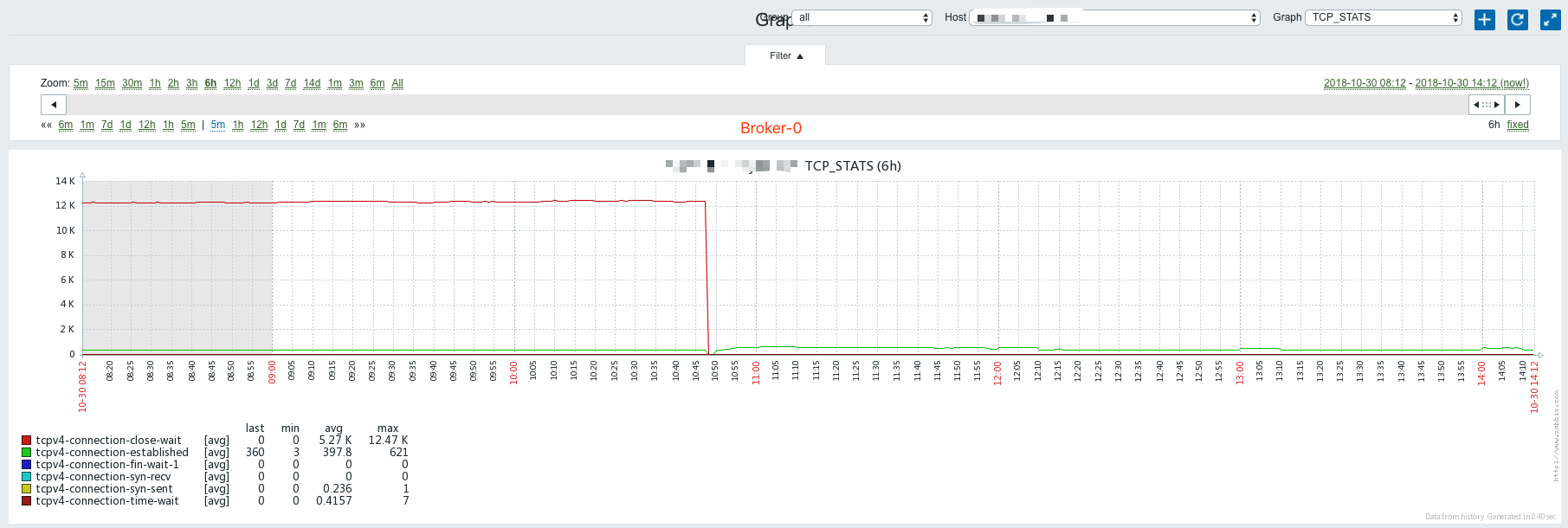
- 在重启
Broker 0后,重启Broker 1及Broker 2前,Broker 1及Broker 2开始出现大量close wait,established数量下降。 - 重启
Broker 1及Broker 2后,Broker 1及Broker 2的close wait消失,established数量出现上升:
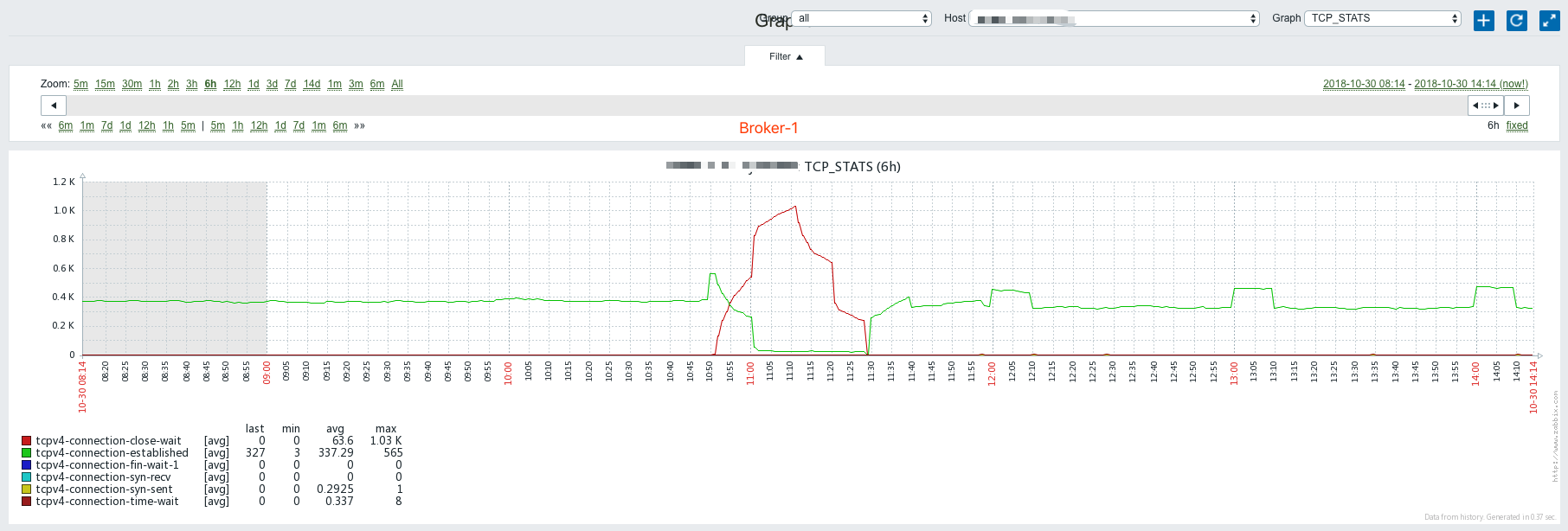
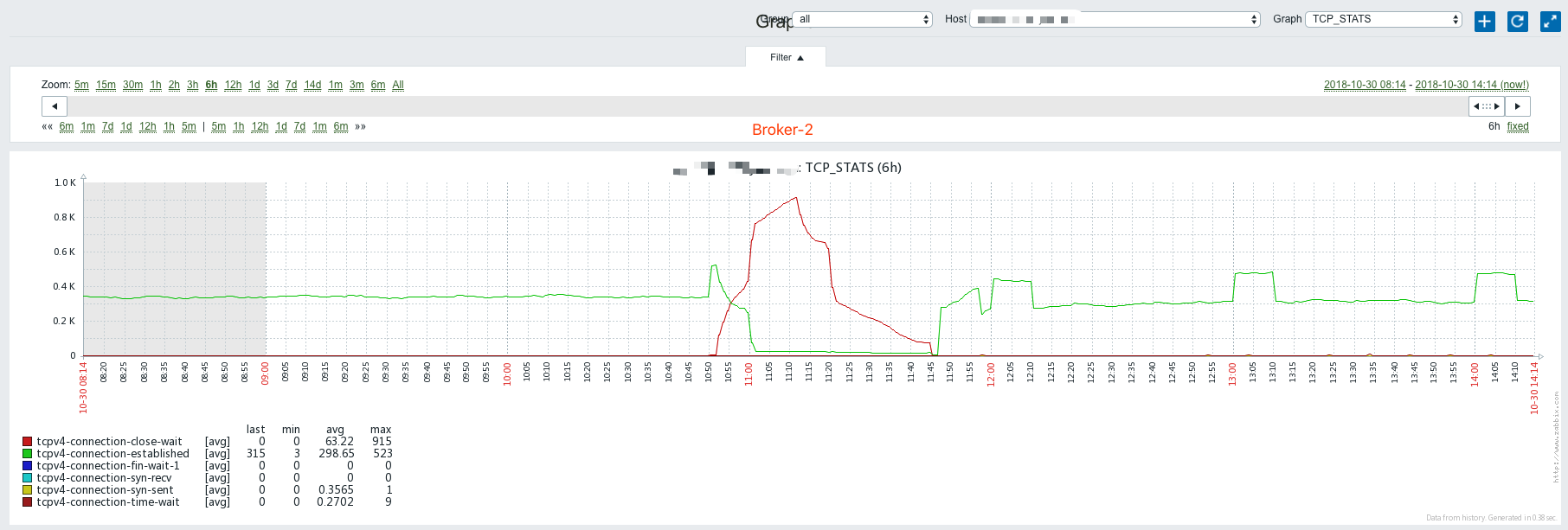
- 每当
close wait数量上升,服务器可用内存同时减少,为维持这些连接,占用了大量内存。
几年前也遇到过类似Kafka close wait数量突增的问题,当时是由于老版本logstash shipper存在bug,导致生产者大量发送无效数据的问题,后通过升级logstash版本解决。而本次的close wait突然升高,究竟是由于网络瞬时波动导致,还是Kafka自身版本问题所导致,这里也是个疑问。
如果后面再次频繁出现同样问题的话,就需要考虑升级kafka版本了。