背景
我司日志系统采用业界普遍的ELK架构,采用Logstash作为Kafka与Elasticsearch间的中间件(以下简称:logstash-indexer),主要用于对原日志的加工处理,包括了日志字段的增、删、改,以及最重要的分割操作。
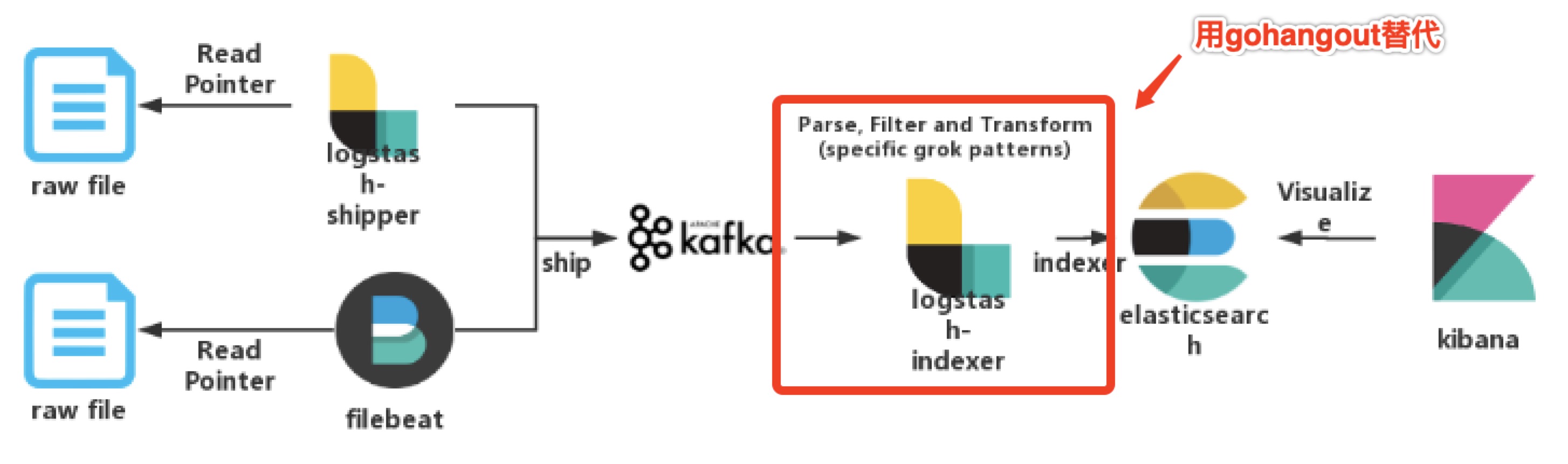
但随着使用量的增加,我们愈加发现logstash-indexer在高并发下的性能瓶颈,到了晚高峰时期ES特别容易出现索引延迟现象,排查后发现其根本原因并非是ES性能达到了瓶颈,而是logstash-indexer作为kafka的消费端出现性能瓶颈,无法及时将kafka中数据传递到es,从而造成了ES索引延迟。
另外logstash使用了java作为开发语言,java框架依赖jvm,而jvm比较耗内存,且在并发量较高的情况下gc会对程序性能造成一定影响。而本文推荐的gohangout使用了go作为开发语言,go的goroutine天生适合高并发处理场景,同时消耗更少内存。
携程的childe同学开源了gohangout,正好符合我们的需求,于是便开始尝试使用,并且在此次测试后发现其性能确实优于logstash——用更少的服务器硬件资源,达到更高的服务效果。
编译及运行
- 下载最新程序代码,并进行编译(需安装go编译环境)并执行:
# yum install go
# cat > /etc/bashrc << EOF
export GOROOT=/usr/local/go
export GOPATH=/home/soft/go
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
EOF
# mkdir /home/soft/go/src/github.com/childe -p
# cd /home/soft/go/src/github.com/childe
# git clone https://github.com/childe/gohangout.git
# cd gohangout/
# govendor sync
# govendor list
# make
# ln -s /home/soft/go/src/github.com/childe/gohangout/build/gohangout /usr/local/bin/gohangout
# vi indexer-kafka-tmp.yml
# gohangout --config indexer-kafka-tmp.yml &
- 下载二进制程序并运行(可在没有go环境的服务器上执行):
# cd /usr/local/bin
# wget https://github.com/childe/gohangout/releases/download/1.2.3/gohangout-linux-x64-4f3153a
# chmod +x gohangout-linux-x64-4f3153a
# vi indexer-kafka-tmp.yml
# gohangout-linux-x64-4f3153a --config indexer-kafka-tmp.yml &
压力测试
为测试gohangout是否能够满足我司线上日志并发需求(某日志索引平均每秒超1万),单独找了2台物理服务器(硬件配置均为:8cores/32G/500G STAT):
- 1台物理服务器部署gohangout服务;
- 1台物理服务器部署es服务;
根据gohangout配置文件参数,能够提供给我们进行配置的参数并不多,主要包括:
bulk_actions:当消费了kafka多少条消息后,向es服务提交一次bulk请求,默认1000;bulk_size:单位是MB,当消费的kafka消息大于等于该值时,向es服务提交一次bulk请求,默认15MB;worker:使用多个线程(goroutine)处理数据,默认一个线程。
另外es服务配置不同,也会影响到索引的效率,主要包括:
shards:es主分片数量;data node:数据节点数量。
根据以上参数,我们分别进行测试,得出以下测试数据:
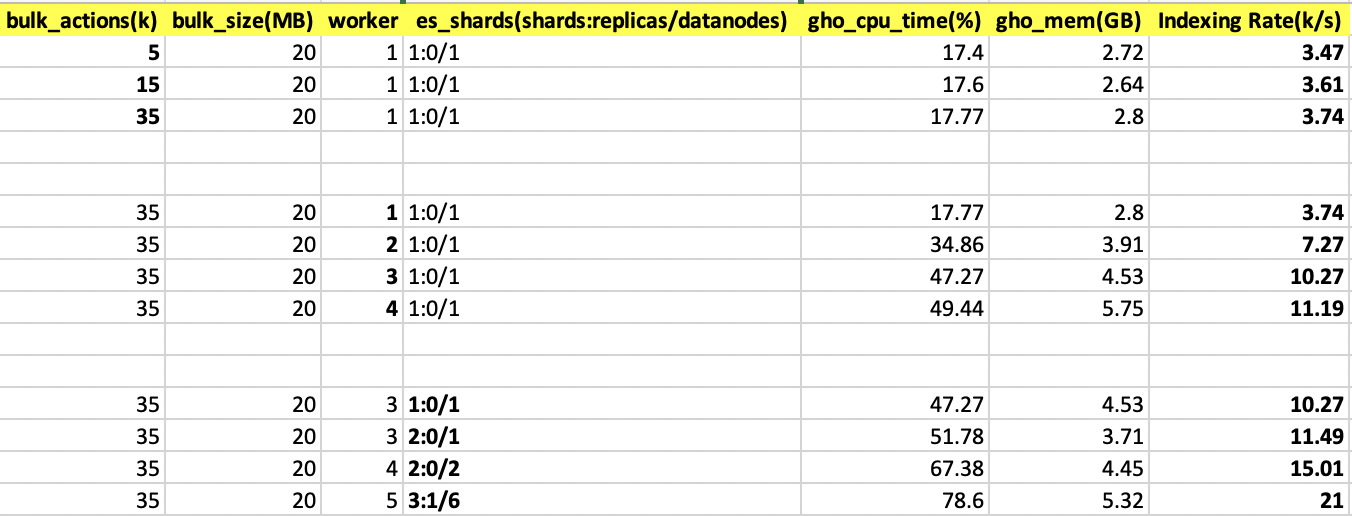
从以上测试数据可以得出以下结论:
bulk_actions越高,索引效率越高
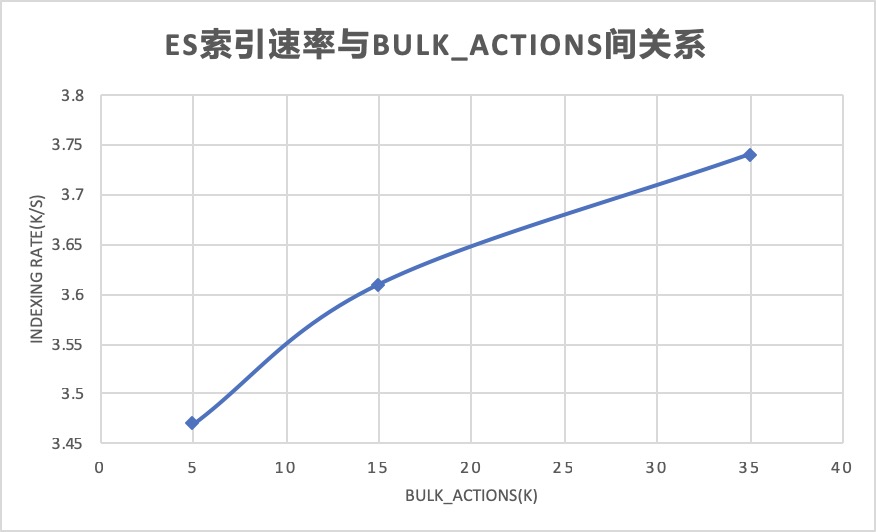
bulk_actions越高,意味着每次向es提交的数据越多,es索引数量也就越高,但测试时发现这个值受es磁盘io影响,越往上es磁盘io越高,超过35,000后索引性能几乎就上不去了,所以在日志大小不同的情况下,需要合理配置该值,最好是索引效率最高,又不写爆es io为最佳。
另外提下bulk_size这个参数,无论bulk_actions配的多高,只要消费kafka日志大小达到这个值,便进行提交,此时无视bulk_actions参数。举例bulk_size=20MB,bulk_actions=35000,按我的日志大小计算,35000条日志的大小已远超20MB,所以提交bulk是无法达到35000这个值的,gohangout会换算到20MB等量的docs数,平均下来在2万4千条到2万5千条左右。
worker越大,索引效率越高
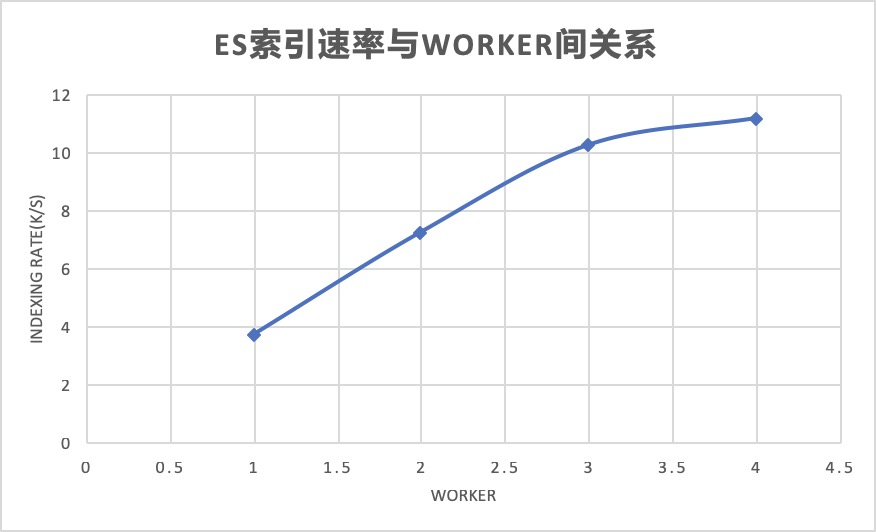
worker数量决定了多少个goroutine线程在跑,每加一,es索引性能几乎翻倍,也即在es性能无限、gohangout cpu、内存、网卡未到达瓶颈的情况下,索引效率几乎可以做到无限翻翻。
es索引分片及es数据节点数量越大,索引效率越高
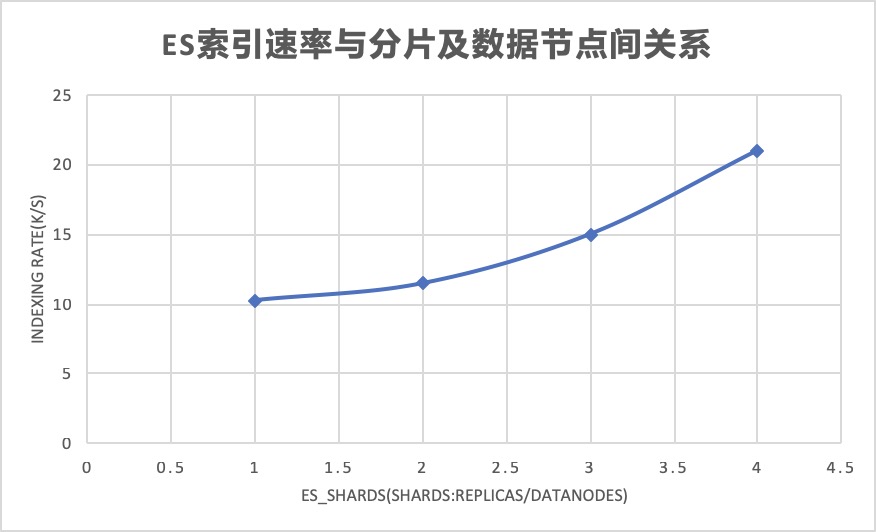
单台es服务器下跑1个分片与2个分片虽然索引效率虽然相差不大(1k左右),但还是可以看到2个分片情况下,es服务器的cpu time/load/disk io都得到了一定的分摊,从而略微提高了es索引效率;但若将2个主分片平均分摊在2个es服务器数据节点上,提升的效果还是比较明显的,一下子大概上升了大概4k左右。
21k索引是最后在线上环境跑出来的结果,线上worker=5已经基本满足我们的需要了。如后期日志量增加,可适当调节worker数进行适配。
消费速度越高,gohangout cpu time及内存消耗越大
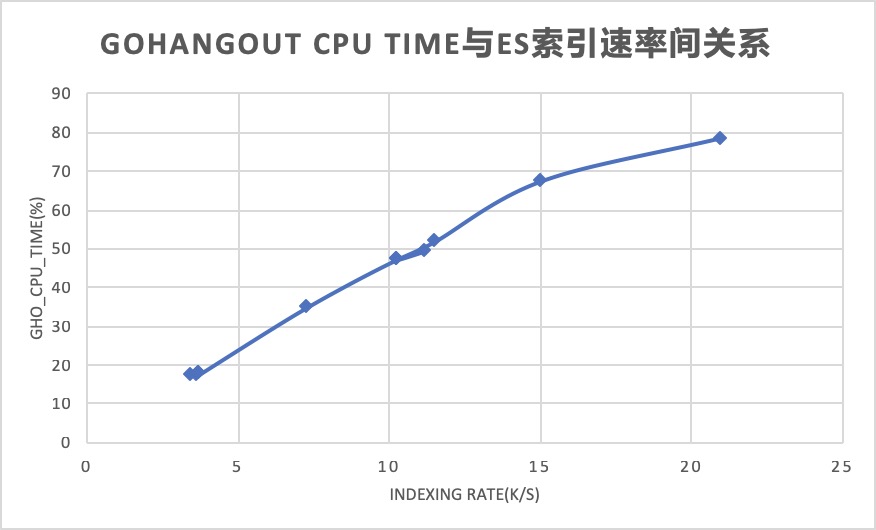
gohangout所在服务器随着消费量的增加,其cpu消耗比较明显,当索引到21k时,cpu time达到了最高的78.6%,几乎没有多少空闲(cpu idle time)了。
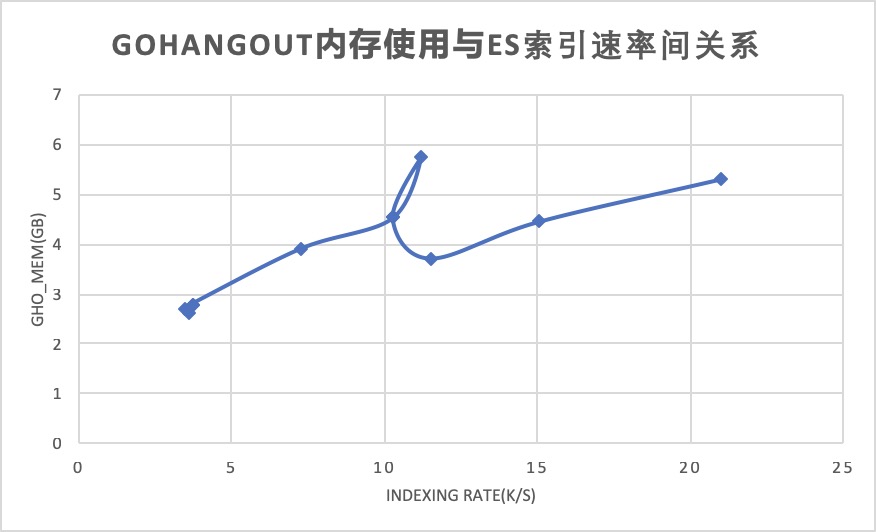
内存相对还好,索引最高的情况下也就用了大概5G多些,相比logstash的十多G可是少了很多了。
还能提升索引效率吗?
如果当gohangout cpu time全部都被耗尽的情况下,如何继续提高索引效率?我能想到三种办法:
- 换一台cpu核数更高的服务器来跑gohangout服务;
- 配置文件中,kafka
topic改为assign,并指定kafka的partition号,单台gohangout服务跑指定分区,多台gohangout一起跑,类似横向扩展的方式进行提升; - 喊childe改代码,提升kafka消费效率,降低cpu time。
遇到的一些问题
go的时间格式
在写配置文件时,date/formats部分的语法必须按照go语言规则来,也就是:2006-01-02 15:04:05,或者2006-01-02T15:04:05,再或者2006 Jan 02 15:04:05,具体格式可以变,但具体日期及时间不能变,是定死的,如果写成:2019 Feb 28 14:44:20,就会date解析失败。
关于毫秒
如果时间中包含毫秒,go时间格式只支持2006-01-02 15:04:05.000这样的格式,如果你的日志时间格式是:2019-03-04T11:15:16,417这样的,那必须拆分处理,如下:
filters:
- Grok:
src: message
match:
- '^(?P<logtime_format>.*?)\,(?P<logtime_ms>.*?)'
- Date:
src: '%{logtime_format}.%{logtime_ms}'
location: 'Asia/Shanghai'
formats:
- '2006-01-02 15:04:05.000'
- '2006-01-02T15:04:05.000'
remove_fields: ["logtime_format","logtime_ms"]
关于自加年份
如果你的日志时间格式是:Feb 28 14:44:20这样的,那可以如下添加年份,gohangout已经帮你取到今年的年份了:
- Date:
src: 'logtime'
location: Asia/Shanghai
add_year: true
formats:
- '2006Jan 2 15:04:05'
remove_fields: ["logtime"]
引用gohangout源码部分,如下实现(date.go):
if dp.addYear {
value = fmt.Sprintf("%d%s", time.Now().Year(), t.(string))
}
关于if写法
与logstash的if用法不太一样,可以照下面这么写:
- Grok:
if:
- 'EQ(source,"sshd")'
src: message
match:
- 'invalid user .*? from (?P<sourceip>[0-9.a-fA-F:]+)'
关于grok正则
正则匹配采集转义字符grok失败,去掉转义符就通过,如日志中包含\n,grok都会失败,解法参照go的正则语法,前面加 (?ms),如下:
(?ms)(?P<message>.*)
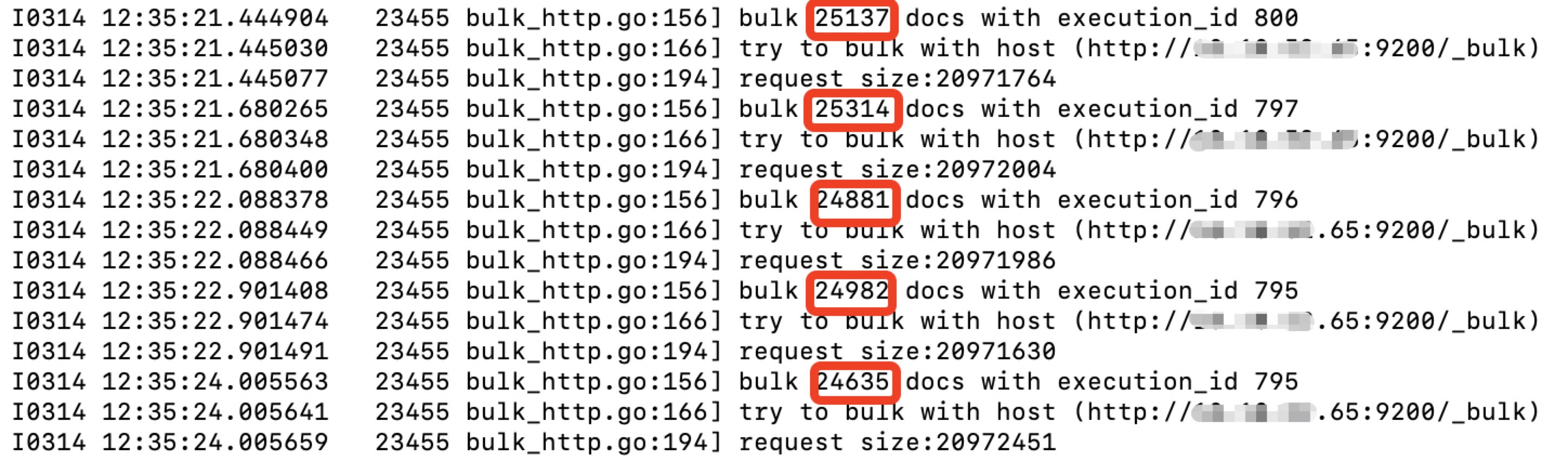
日志中为何出现多组execution_id
如果出现了下面的情况,说明有多个output:
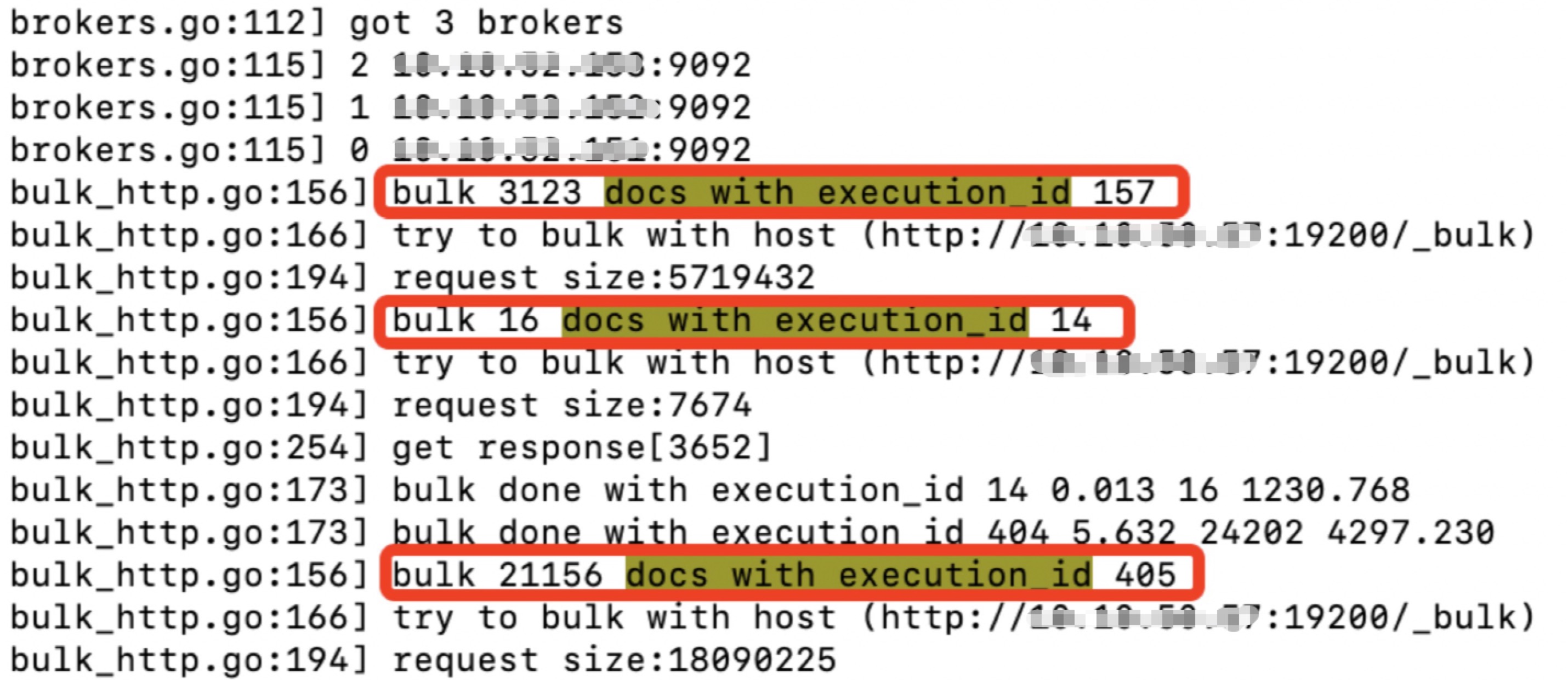
es集群磁盘io瓶颈?
配ssd,translog用异步, refresh设置60s等。
group_id不变情况下采集最新数据?
- 删group_id
- 用reset offset
索引到先前logstash传输的索引数据出现兼容性问题?
如果启动gohangout报如下错:
I0314 10:23:27.736730 21658 elasticsearch_output.go:141] error :map[reason:Rejecting mapping update to [logstash-xxx-2019.03.14] as the final mapping would have more than 1 type: [doc, logs] type:illegal_argument_exception]
logstash中默认索引type为:doc,而gohangout中index_type字段默认为:logs,需改成doc才能索引至原先索引数据。
上线效果
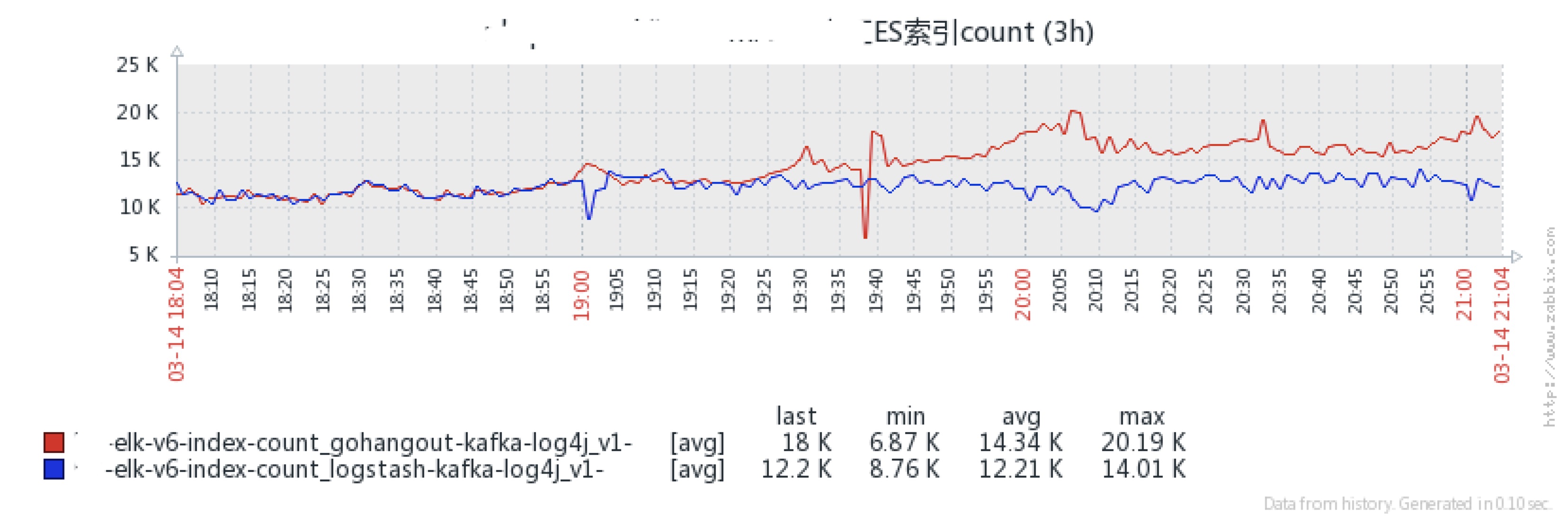
红线为gohangout的索引曲线,蓝线为logstash的索引曲线,蓝线所在索引已出现延迟,红线索引状态良好,线上效果已得到验证,相同日志数量下gohangout性能优于logstash。
注:这边不是说logstash达不到这个消费能力,只是说明logstash还存在优化的空间,而我们用gohangout却可以很轻松的达到。
最后
gohangout的github地址为:https://github.com/childe/gohangout ,十分不错的一款日志传输工具,有相同需要的欢迎来尝试:)