背景
某机房ES集群近期一到晚高峰,索引速度出现不稳定情况,这段时间内ES可用性降低,无论数据索引还是查询,都会出现慢或超时的情况。
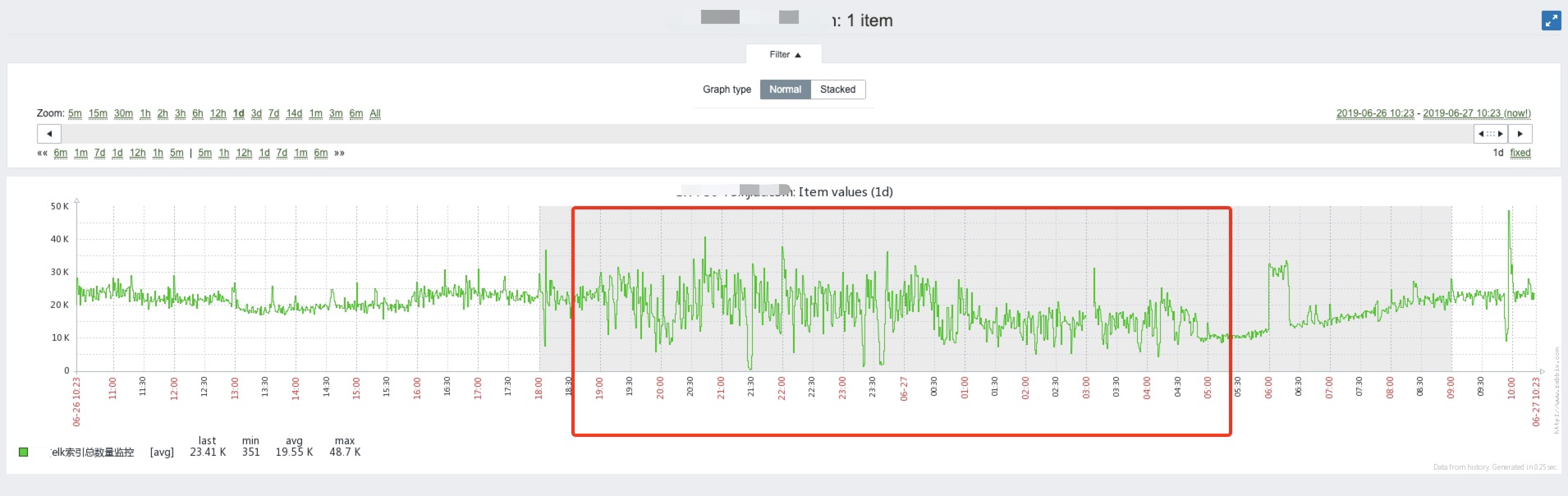
问题
登录集群中某es节点服务器,查询es日志发现很多集群内部通信异常的报错,我们挑几个贴出来:
[2019-06-26T18:39:10,870][WARN ][o.e.t.n.Netty4Transport ] [x.x.50.187] write and flush on the network layer failed (channel: [id: 0xe5b7c77e, L:/x.x.50.187:9300 ! R:/x.x.50.79:42673])
java.io.IOException: Connection timed out
at sun.nio.ch.FileDispatcherImpl.writev0(Native Method) ~[?:?]
at sun.nio.ch.SocketDispatcher.writev(SocketDispatcher.java:51) ~[?:?]
at sun.nio.ch.IOUtil.write(IOUtil.java:148) ~[?:?]
at sun.nio.ch.SocketChannelImpl.write(SocketChannelImpl.java:504) ~[?:?]
at io.netty.channel.socket.nio.NioSocketChannel.doWrite(NioSocketChannel.java:432) ~[netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.AbstractChannel$AbstractUnsafe.flush0(AbstractChannel.java:856) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.AbstractNioChannel$AbstractNioUnsafe.forceFlush(AbstractNioChannel.java:368) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:638) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeysPlain(NioEventLoop.java:544) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:498) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:458) [netty-transport-4.1.13.Final.jar:4.1.13.Final]
at io.netty.util.concurrent.SingleThreadEventExecutor$5.run(SingleThreadEventExecutor.java:858) [netty-common-4.1.13.Final.jar:4.1.13.Final]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_131]
...
[2019-06-26T18:39:10,913][WARN ][o.e.t.n.Netty4Transport ] [x.x.50.187] write and flush on the network layer failed (channel: [id: 0xe5b7c77e, L:/x.x.50.187:9300 ! R:/x.x.50.79:42673])
java.nio.channels.ClosedChannelException: null
at io.netty.channel.AbstractChannel$AbstractUnsafe.write(...)(Unknown Source) ~[?:?]
我们推测由于主分片同步副本时,瞬时突发大流量打满网卡,导致集群间通信出现异常,随后分片数据收到影响被迫脱离集群,随即又触发了分片重平衡,我们抓取了对应交换机端口流量数据:
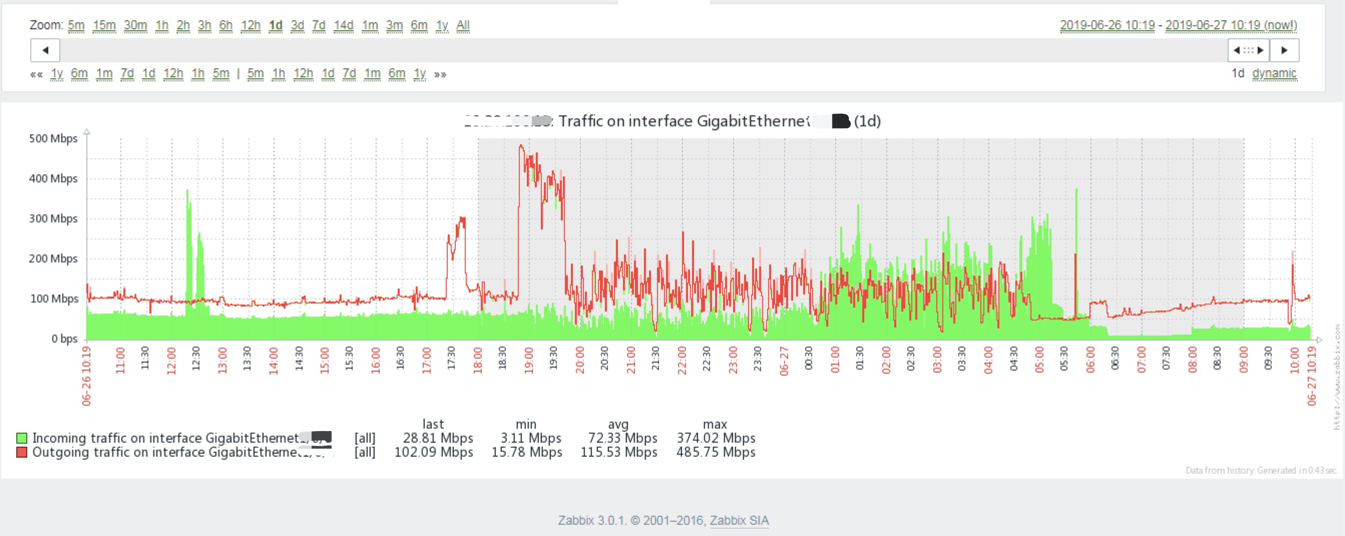
可以看出6点半开始陆续出现通信异常,6点45分左右分片应该是有分片数据丢失(可能是主分片,也可能是副本,具体要现场观察),从而导致了分片数据重平衡。
另外,值得补充的是,虽说服务器是千兆网卡,但实际也不一定能全部达到1000Mbps,其带宽受限于服务器网卡及驱动、交换机硬件及系统版本、广播、arp包、坏包重传、网线光纤等物理因素造成丢包重传,从而造成带宽还没到1000M就出现瓶颈的情况。
缓解
针对该问题,我们觉得有以下几种方法能够缓解:
- 服务器、交换机网卡由千兆换成万兆;
- 不保留副本,只保存主分片,但如果集群节点宕机,可能存在数据丢失问题;
- 对es集群副本传输速度限流(可参照
indices.recovery.max_bytes_per_sec该配置项),可能造成副本拷贝速度变慢,但成本最小; - 增加es数据节点,减少分片传输大小,间接减少网络传输的峰值带宽;
当前我们将重要程度不高的数据配置为0副本,即便丢失也不会有太大影响,待今晚再观察下es表现情况。
参考文档
ElasticSearch线上故障-持续Yellow状态
Indices Recovery
iperf download
iperf sample command line usage
网络带宽和质量测试小工具.iPerf3