背景
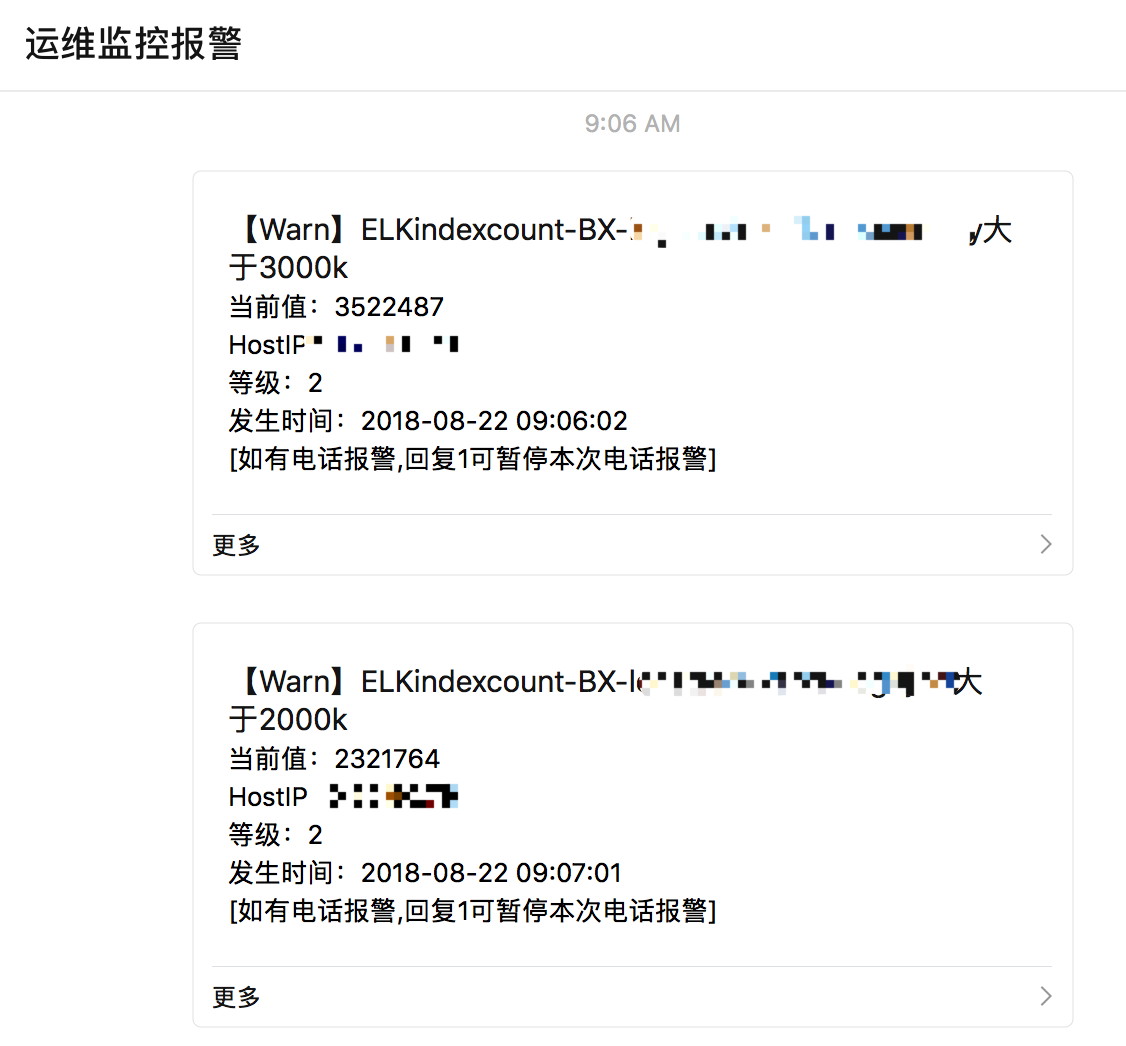
一早上班就接到微信ELK索引量报警,该报警逻辑是监控5分钟内各个索引的数量,我们主要以这个性能指标来衡量ELK运行状态。
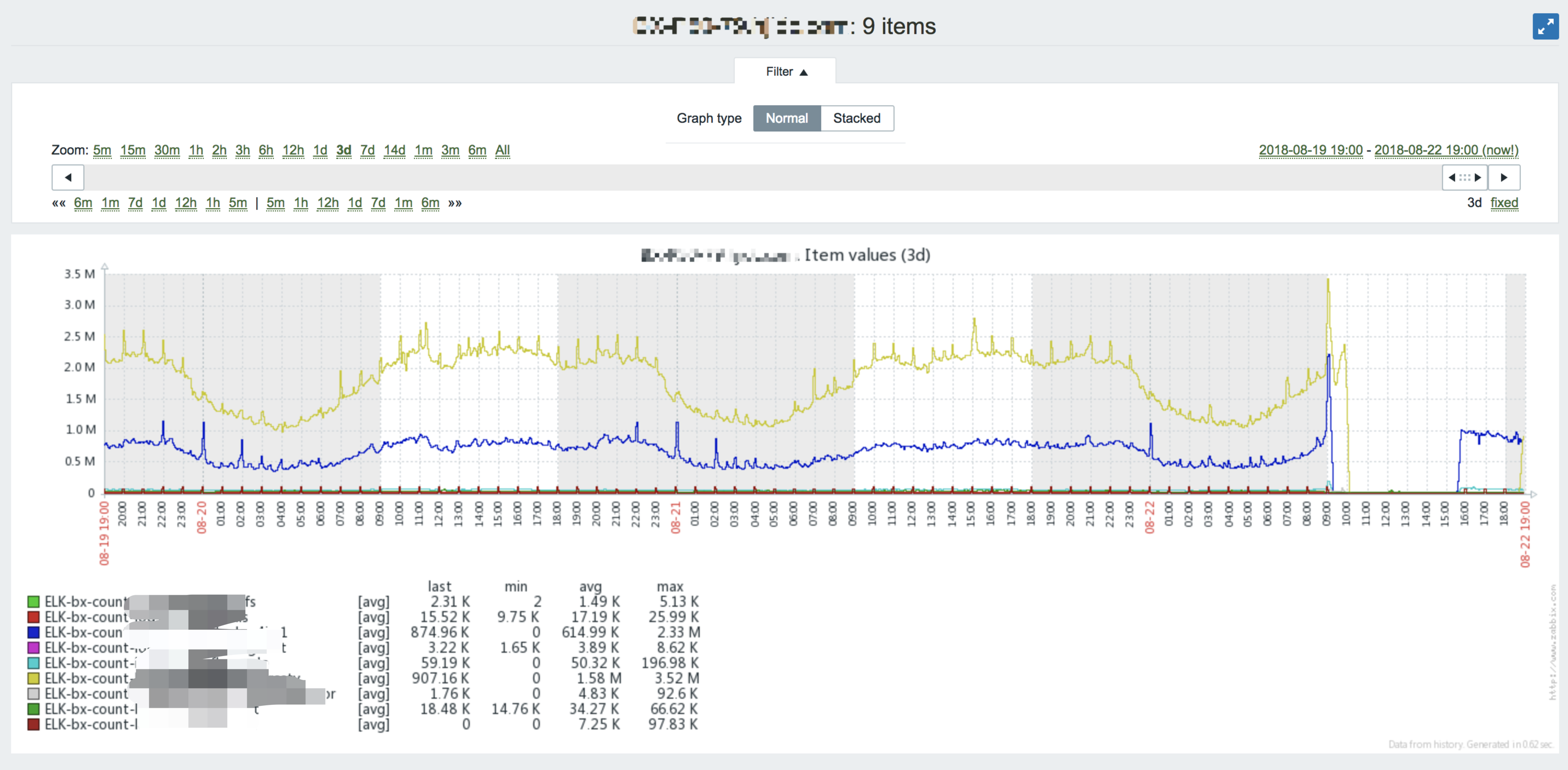
9点06分的时候索引量突增超阈值报警:
9点24分的时候索引量跌至0:

跌落至0后未自行恢复,感觉有点不太妙。
问题
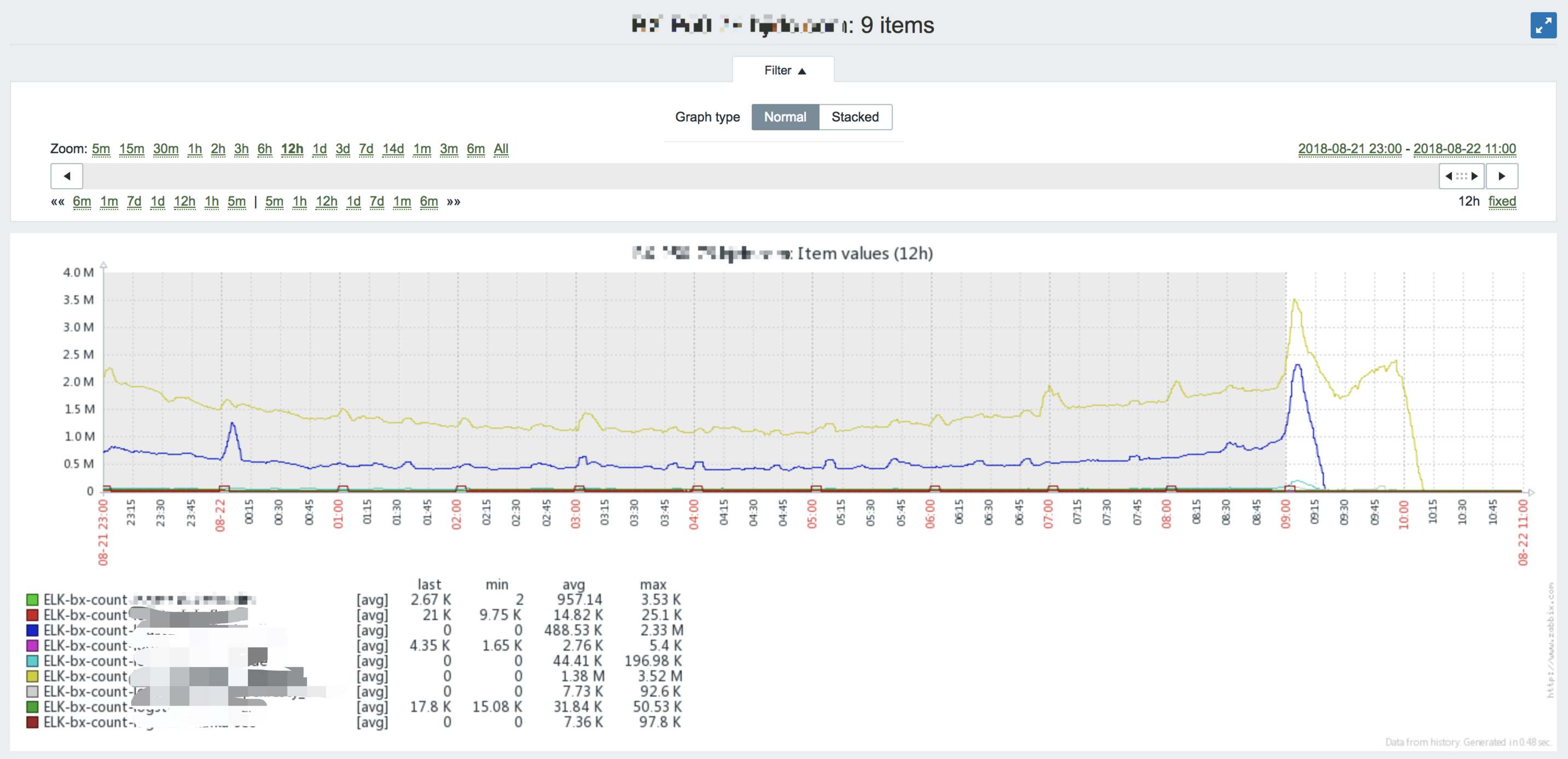
看报警内容,又看了下zabbix图,发现9点的时候索引量明显突增,基本达到了均值的1.5倍!
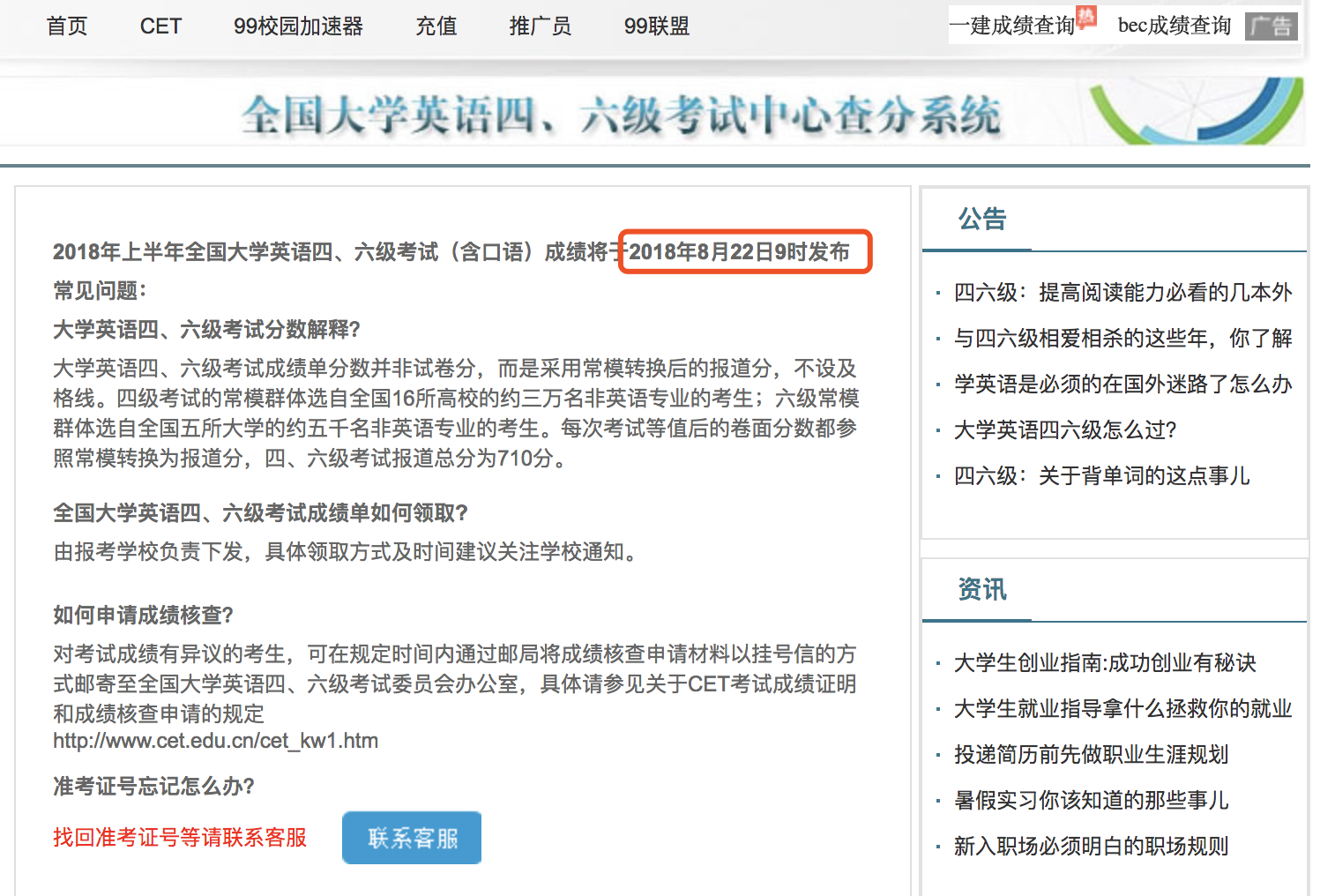
在找到了日志量异常的站点域名后,立即反馈问题到架构部门,架构同学联系响应开发,后确认是由于今天英语四六级查分导致。
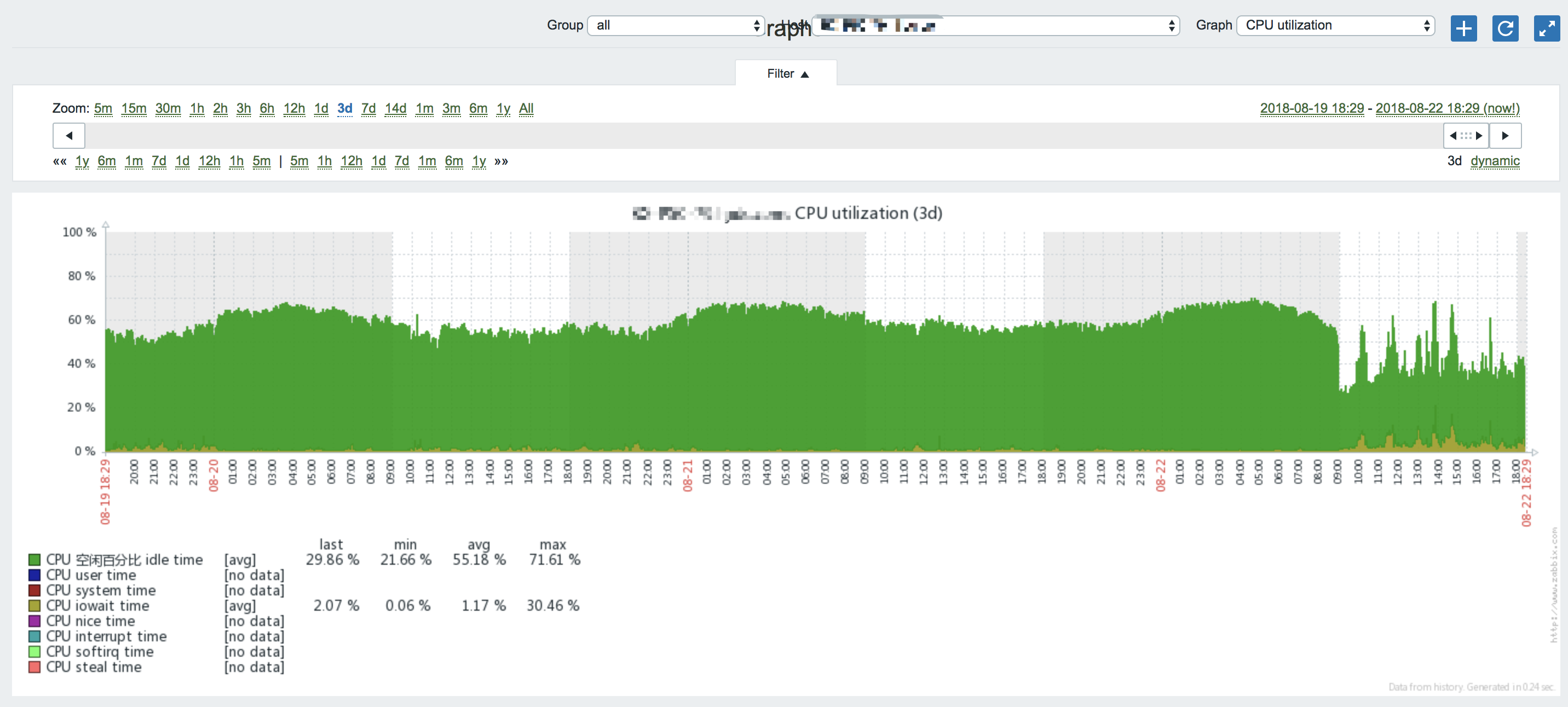
具体再看ES集群CPU利用率,9点开始CPU明显吃紧,同时伴有cpu io wait,虽然这台机器是32核的,但还是拖不动了!
缓解
由于业务方并未提前通知,并且机房也没有闲置的高配的机器可以随时扩容。
所以很遗憾,这边无能为力,只能让ES慢慢跑,等自己消化掉。
最后一直到晚7点左右,ES索引才完全恢复。
后记
业务方在遇到类似可预期的突发请求时,必须提前进行扩容。
运维也需要备足几台机器,随时可以进行扩容,以保证服务可用性。