背景
为配合我司服务器利用率服务上线,需要在某机房所有Linux服务器上线客户端脚本,脚本本身十分简单,就一个Go程序,同时下发启动命令,以及添加开机自启配置。
这个脚本已经在其他几个机房上线过了,基本没遇到什么问题,很顺利就上线了,而今天却遇到了幺蛾子。
问题
中午网络组突然接到几个产线开发反馈,说是服务器有丢包,造成程序异常。包括我自己也受到了报警。
已经稳定跑了将近1个月的ELK集群,突然报索引跌至0的报警。看了下机器流量图,判断集群状态不稳定:
Logstash-Indexer网卡入流量异常:
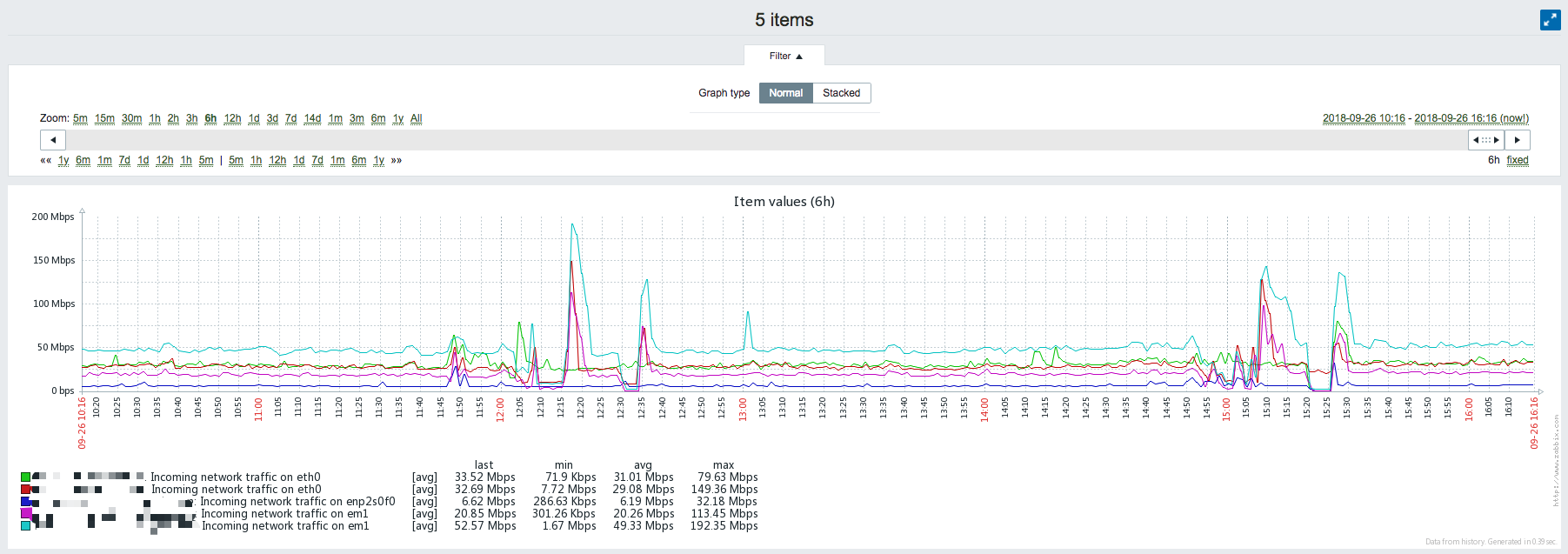
ES DATA NODE网卡入流量异常:
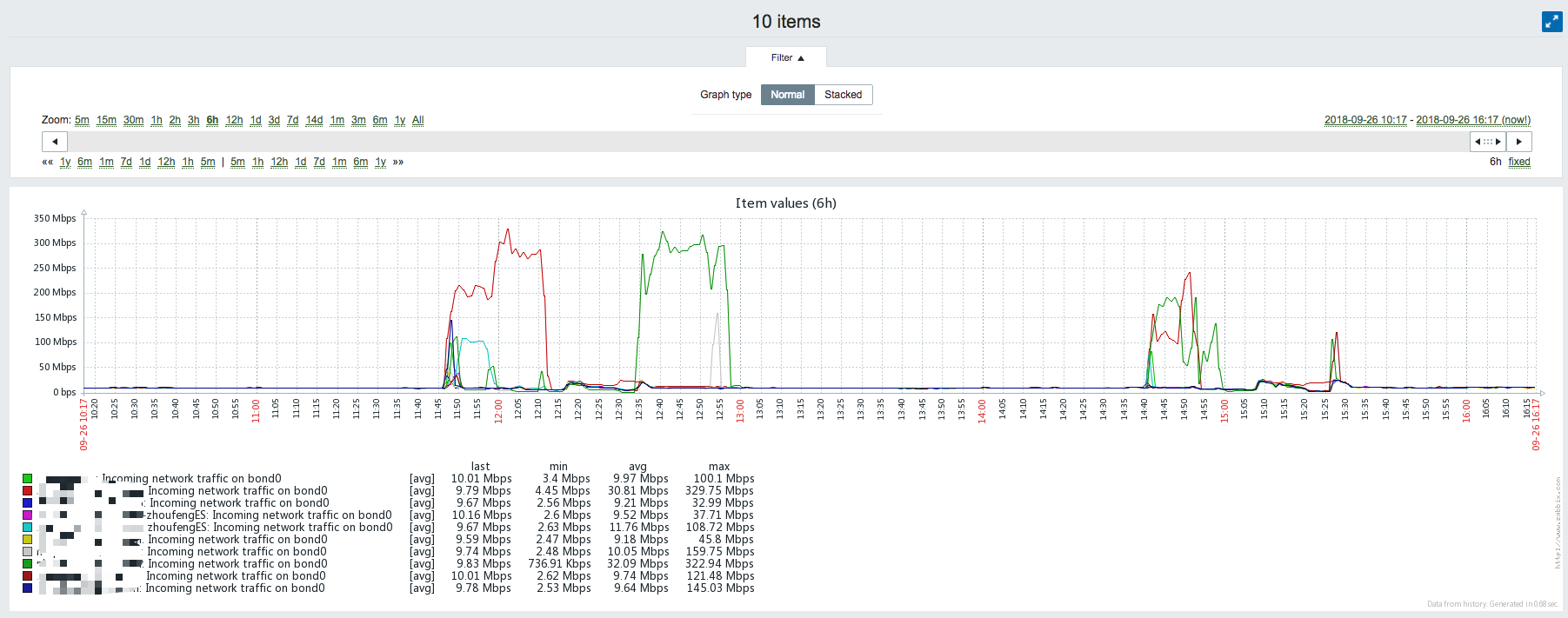
上服务器查看了下业务日志,发现与其他产线类似,日志中有节点通信失败的异常:
[2018-09-26 14:40:47,756][WARN ][action.bulk ] [elastic_inst6] failed to perform indices:data/write/bulk[s] on remote replica [elastic_inst12][bWovbLsuRuWnKa90exyoVg][localhost][inet[/<es12_ip>:9300]]{master=false}[logstash-kafka-iis-2018.09.26][0]
org.elasticsearch.transport.SendRequestTransportException: [elastic_inst12][inet[/<es12_ip>:9300]][indices:data/write/bulk[s][r]]
at org.elasticsearch.transport.TransportService.sendRequest(TransportService.java:286)
at org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$ReplicationPhase.performOnReplica(TransportShardReplicationOperationAction.java:877)
at org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$ReplicationPhase.doRun(TransportShardReplicationOperationAction.java:854)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:36)
at org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$PrimaryPhase.finishAndMoveToReplication(TransportShardReplicationOperationAction.java:525)
at org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$PrimaryPhase.performOnPrimary(TransportShardReplicationOperationAction.java:603)
at org.elasticsearch.action.support.replication.TransportShardReplicationOperationAction$PrimaryPhase$1.doRun(TransportShardReplicationOperationAction.java:440)
at org.elasticsearch.common.util.concurrent.AbstractRunnable.run(AbstractRunnable.java:36)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.elasticsearch.transport.NodeNotConnectedException: [elastic_inst12][inet[/<es12_ip>:9300]] Node not connected
at org.elasticsearch.transport.netty.NettyTransport.nodeChannel(NettyTransport.java:964)
at org.elasticsearch.transport.netty.NettyTransport.sendRequest(NettyTransport.java:656)
at org.elasticsearch.transport.TransportService.sendRequest(TransportService.java:276)
... 10 more
将异常时间、源目的IP反馈到网络组后,网络组开始排查,但随后确认交换机日志并未出现异常,监控也并未显示明显异常,推测是由于设备性能问题引起的短时偶发丢包。
我突然想到了自己在该机房进行salt批量任务下发操作,似乎是我挖的坑…
我是针对机房操作系统进行灰度任务下发的,CentOS7.X一批,CentOS6.5一批,CentOS6.8一批,每批少则几十台,多则几百台,每次在批量推送任务时,salt-master将任务下发至所有对象服务器,对象服务器向salt-master发起文件拉取操作。由于目标服务器散布在不同机柜,机柜间数据传输会过核心交换机,在这短暂的时间里,核心交换机承受较大并发压力,间接影响其他正常服务通信,造成线上业务程序出现超时丢包情况。
缓解
由于拿不准批量多少会造成瓶颈,这边干脆调整下发逻辑,由原来的灰度发布,改成脚本自动跑循环,以15秒为间隔,一台台跑,慢点就慢点,确保对线上没影响。
后记
各机房网络设备性能不一,所以即便在其他机房测试过这个部署脚本,但也不意味着在所有机房都通用。类似由于salt批量下发文件导致带宽跑满的问题也不止一次了,这次又栽在这里了,想想还有点后怕,万一把核心交换机打趴了咋整,丢包影响到核心DB甚至导致VIP漂移咋整……
这边还是需要强化下salt批量执行任务的规范:
- 无论下发的任务复杂与否,都必须先跑一台测试下,测试没问题后,再进行灰度发布;
- 灰度可以从各种角度出发,包括:以机房区分、以操作系统版本区分、以网段区分等;
- 涉及到消耗网络带宽的文件下发、部署等任务时,必须用for循环跑,禁止批量同时下发。
最后,还请对线上抱有敬畏之心!